+ ![]() +
+
+ +
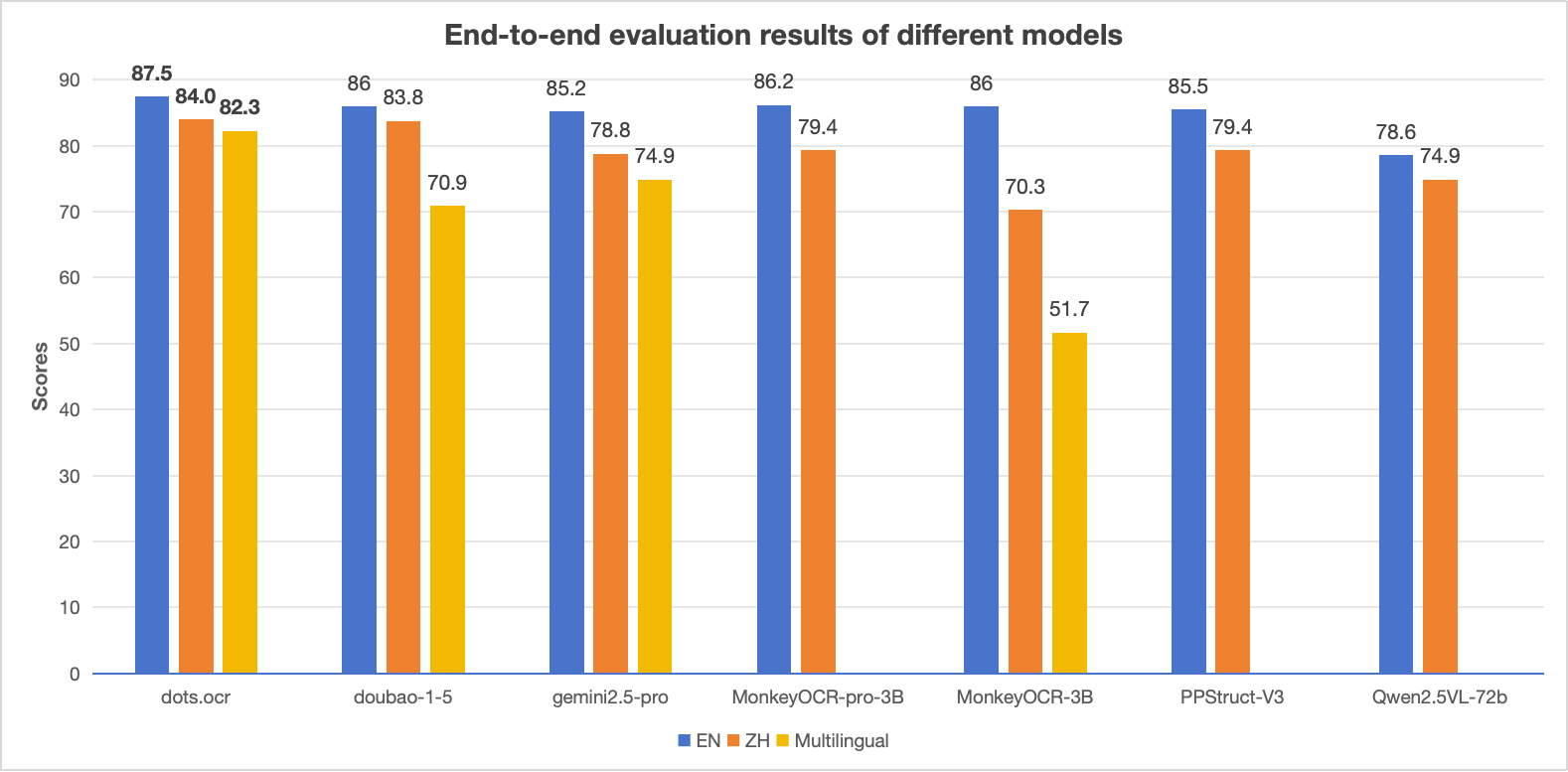 -
-> **Notes:**
-> - The EN, ZH metrics are the end2end evaluation results of [OmniDocBench](https://github.com/opendatalab/OmniDocBench), and Multilingual metric is the end2end evaluation results of dots.ocr-bench.
-
+**dots.ocr** Designed for universal accessibility, it possesses the capability to recognize virtually any human script. Beyond achieving state-of-the-art (SOTA) performance in standard multilingual document parsing among models of comparable size, dots.ocr-1.5 excels at converting structured graphics (e.g., charts and diagrams) directly into SVG code, parsing web screens and spotting scene text.
## News
-* ```2025.10.31 ``` 🚀 We release [dots.ocr.base](https://huggingface.co/rednote-hilab/dots.ocr.base), foundation VLM focus on OCR tasks, also the base model of [dots.ocr](https://github.com/rednote-hilab/dots.ocr). Try it out!
-* ```2025.07.30 ``` 🚀 We release [dots.ocr](https://github.com/rednote-hilab/dots.ocr), — a multilingual documents parsing model based on 1.7b llm, with SOTA performance.
+* ```2026.2.16 ``` 🚀 We release [dots.ocr-1.5](https://huggingface.co/rednote-hilab/dots.ocr-1.5), trying to recognize any human scripts and symbols, not only the document parsing, but also the image parsing. We are simultaneously releasing [dots.ocr-1.5-svg](https://huggingface.co/rednote-hilab/dots.ocr-1.5-svg), which has more robust performance on image parsing
+* ```2025.10.31 ``` 🚀 We release [dots.ocr.base](https://huggingface.co/rednote-hilab/dots.ocr.base), foundation VLM focus on OCR tasks, also the base model of [dots.ocr](https://huggingface.co/rednote-hilab/dots.ocr). Try it out!
+* ```2025.07.30 ``` 🚀 We release [dots.ocr](https://huggingface.co/rednote-hilab/dots.ocr), — a multilingual documents parsing model based on 1.7b llm, with SOTA performance.
-## Benchmark Results
-### 1. OmniDocBench
+## Evaluation
-#### The end-to-end evaluation results of different tasks.
+### 1. Document Parsing
+
+#### 1.1 Elo Score of different bench between latest models
+
+
-
-> **Notes:**
-> - The EN, ZH metrics are the end2end evaluation results of [OmniDocBench](https://github.com/opendatalab/OmniDocBench), and Multilingual metric is the end2end evaluation results of dots.ocr-bench.
-
+**dots.ocr** Designed for universal accessibility, it possesses the capability to recognize virtually any human script. Beyond achieving state-of-the-art (SOTA) performance in standard multilingual document parsing among models of comparable size, dots.ocr-1.5 excels at converting structured graphics (e.g., charts and diagrams) directly into SVG code, parsing web screens and spotting scene text.
## News
-* ```2025.10.31 ``` 🚀 We release [dots.ocr.base](https://huggingface.co/rednote-hilab/dots.ocr.base), foundation VLM focus on OCR tasks, also the base model of [dots.ocr](https://github.com/rednote-hilab/dots.ocr). Try it out!
-* ```2025.07.30 ``` 🚀 We release [dots.ocr](https://github.com/rednote-hilab/dots.ocr), — a multilingual documents parsing model based on 1.7b llm, with SOTA performance.
+* ```2026.2.16 ``` 🚀 We release [dots.ocr-1.5](https://huggingface.co/rednote-hilab/dots.ocr-1.5), trying to recognize any human scripts and symbols, not only the document parsing, but also the image parsing. We are simultaneously releasing [dots.ocr-1.5-svg](https://huggingface.co/rednote-hilab/dots.ocr-1.5-svg), which has more robust performance on image parsing
+* ```2025.10.31 ``` 🚀 We release [dots.ocr.base](https://huggingface.co/rednote-hilab/dots.ocr.base), foundation VLM focus on OCR tasks, also the base model of [dots.ocr](https://huggingface.co/rednote-hilab/dots.ocr). Try it out!
+* ```2025.07.30 ``` 🚀 We release [dots.ocr](https://huggingface.co/rednote-hilab/dots.ocr), — a multilingual documents parsing model based on 1.7b llm, with SOTA performance.
-## Benchmark Results
-### 1. OmniDocBench
+## Evaluation
-#### The end-to-end evaluation results of different tasks.
+### 1. Document Parsing
+
+#### 1.1 Elo Score of different bench between latest models
+
+| models | +olmOCR-Bench | +OmniDocBench (v1.5) | +XDocParse | +
|---|---|---|---|
| GLM-OCR | +859.9 | +937.5 | +742.1 | +
| PaddleOCR-VL-1.5 | +873.6 | +965.6 | +797.6 | +
| HuanyuanOCR | +978.9 | +974.4 | +895.9 | +
| dots.ocr | +1027.4 | +994.7 | +1133.4 | +
| dots.ocr-1.5 | +1089.0 | +1025.8 | +1157.1 | +
| Gemini 3 Pro | +1171.2 | +1102.1 | +1273.9 | +
| Model Type |
-Methods | -OverallEdit↓ | -TextEdit↓ | -FormulaEdit↓ | -TableTEDS↑ | -TableEdit↓ | -Read OrderEdit↓ | -||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | -ZH | -EN | -ZH | -EN | -ZH | -EN | -ZH | -EN | -ZH | -EN | -ZH | -||
| Pipeline Tools |
-MinerU | -0.150 | -0.357 | -0.061 | -0.215 | -0.278 | -0.577 | -78.6 | -62.1 | -0.180 | -0.344 | -0.079 | -0.292 | -
| Marker | -0.336 | -0.556 | -0.080 | -0.315 | -0.530 | -0.883 | -67.6 | -49.2 | -0.619 | -0.685 | -0.114 | -0.340 | -|
| Mathpix | -0.191 | -0.365 | -0.105 | -0.384 | -0.306 | -0.454 | -77.0 | -67.1 | -0.243 | -0.320 | -0.108 | -0.304 | -|
| Docling | -0.589 | -0.909 | -0.416 | -0.987 | -0.999 | -1 | -61.3 | -25.0 | -0.627 | -0.810 | -0.313 | -0.837 | -|
| Pix2Text | -0.320 | -0.528 | -0.138 | -0.356 | -0.276 | -0.611 | -73.6 | -66.2 | -0.584 | -0.645 | -0.281 | -0.499 | -|
| Unstructured | -0.586 | -0.716 | -0.198 | -0.481 | -0.999 | -1 | -0 | -0.06 | -1 | -0.998 | -0.145 | -0.387 | -|
| OpenParse | -0.646 | -0.814 | -0.681 | -0.974 | -0.996 | -1 | -64.8 | -27.5 | -0.284 | -0.639 | -0.595 | -0.641 | -|
| PPStruct-V3 | -0.145 | -0.206 | -0.058 | -0.088 | -0.295 | -0.535 | -- | -- | -0.159 | -0.109 | -0.069 | -0.091 | -|
| Expert VLMs |
-GOT-OCR | -0.287 | -0.411 | -0.189 | -0.315 | -0.360 | -0.528 | -53.2 | -47.2 | -0.459 | -0.520 | -0.141 | -0.280 | -
| Nougat | -0.452 | -0.973 | -0.365 | -0.998 | -0.488 | -0.941 | -39.9 | -0 | -0.572 | -1.000 | -0.382 | -0.954 | -|
| Mistral OCR | -0.268 | -0.439 | -0.072 | -0.325 | -0.318 | -0.495 | -75.8 | -63.6 | -0.600 | -0.650 | -0.083 | -0.284 | -|
| OLMOCR-sglang | -0.326 | -0.469 | -0.097 | -0.293 | -0.455 | -0.655 | -68.1 | -61.3 | -0.608 | -0.652 | -0.145 | -0.277 | -|
| SmolDocling-256M | -0.493 | -0.816 | -0.262 | -0.838 | -0.753 | -0.997 | -44.9 | -16.5 | -0.729 | -0.907 | -0.227 | -0.522 | -|
| Dolphin | -0.206 | -0.306 | -0.107 | -0.197 | -0.447 | -0.580 | -77.3 | -67.2 | -0.180 | -0.285 | -0.091 | -0.162 | -|
| MinerU 2 | -0.139 | -0.240 | -0.047 | -0.109 | -0.297 | -0.536 | -82.5 | -79.0 | -0.141 | -0.195 | -0.069< | -0.118 | -|
| OCRFlux | -0.195 | -0.281 | -0.064 | -0.183 | -0.379 | -0.613 | -71.6 | -81.3 | -0.253 | -0.139 | -0.086 | -0.187 | -|
| MonkeyOCR-pro-3B | -0.138 | -0.206 | -0.067 | -0.107 | -0.246 | -0.421 | -81.5 | -87.5 | -0.139 | -0.111 | -0.100 | -0.185 | -|
| + | ArXiv | +Old scans math | +Tables | +Old scans | +Headers & footers | +Multi column | +Long tiny text | +Base | +Overall | +||||
| Mistral OCR API | +77.2 | +67.5 | +60.6 | +29.3 | +93.6 | +71.3 | +77.1 | +99.4 | +72.0±1.1 | +||||
| Marker 1.10.1 | +83.8 | +66.8 | +72.9 | +33.5 | +86.6 | +80.0 | +85.7 | +99.3 | +76.1±1.1 | +||||
| MinerU 2.5.4* | +76.6 | +54.6 | +84.9 | +33.7 | +96.6 | +78.2 | +83.5 | +93.7 | +75.2±1.1 | +||||
| DeepSeek-OCR | +77.2 | +73.6 | +80.2 | +33.3 | +96.1 | +66.4 | +79.4 | +99.8 | +75.7±1.0 | +||||
| Nanonets-OCR2-3B | +75.4 | +46.1 | +86.8 | +40.9 | +32.1 | +81.9 | +93.0 | +99.6 | +69.5±1.1 | +||||
| PaddleOCR-VL* | +85.7 | +71.0 | +84.1 | +37.8 | +97.0 | +79.9 | +85.7 | +98.5 | +80.0±1.0 | +||||
| Infinity-Parser 7B* | +84.4 | +83.8 | +85.0 | +47.9 | +88.7 | +84.2 | +86.4 | +99.8 | +82.5±? | +||||
| olmOCR v0.4.0 | +83.0 | +82.3 | +84.9 | +47.7 | +96.1 | +83.7 | +81.9 | +99.7 | +82.4±1.1 | +||||
| Chandra OCR 0.1.0* | +82.2 | +80.3 | +88.0 | +50.4 | +90.8 | +81.2 | +92.3 | +99.9 | +83.1±0.9 | +||||
| dots.ocr | +82.1 | +64.2 | +88.3 | +40.9 | +94.1 | +82.4 | +81.2 | +99.5 | +79.1% ± 1.0% | +||||
| dots.ocr-1.5 | +85.9 | +85.5 | +90.7 | +48.2 | +94.0 | +85.3 | +81.6 | +99.7 | +83.9% ± 0.9 | +||||
| Qwen2-VL-72B | -0.252 | -0.327 | -0.096 | -0.218 | -0.404 | -0.487 | -76.8 | -76.4 | -0.387 | -0.408 | -0.119 | -0.193 | +Model Type | +Methods | +Size | +OmniDocBench(v1.5) TextEdit↓ |
+ OmniDocBench(v1.5) Read OrderEdit↓ |
+ pdf-parse-bench | +
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GeneralVLMs | +Gemini-2.5 Pro | +- | +0.075 | +0.097 | +9.06 | |||||||||||||
| Qwen2.5-VL-72B | -0.214 | -0.261 | -0.092 | -0.18 | -0.315 | -0.434 | -82.9 | -83.9 | -0.341 | -0.262 | -0.106 | -0.168 | +Qwen3-VL-235B-A22B-Instruct | +235B | +0.069 | +0.068 | +9.71 | |
| Gemini2.5-Pro | -0.148 | -0.212 | -0.055 | -0.168 | -0.356 | -0.439 | -85.8 | -86.4 | -0.13 | -0.119 | -0.049 | -0.121 | +gemini3pro | +- | +0.066 | +0.079 | +9.68 | +|
| SpecializedVLMs | +Mistral OCR | +- | +0.164 | +0.144 | +8.84 | |||||||||||||
| doubao-1-5-thinking-vision-pro-250428 | -0.140 | -0.162 | -0.043 | -0.085 | -0.295 | -0.384 | -83.3 | -89.3 | -0.165 | -0.085 | +Deepseek-OCR | +3B | +0.073 | +0.086 | +8.26 | +|||
| MonkeyOCR-3B | +3B | +0.075 | +0.129 | +9.27 | +||||||||||||||
| OCRVerse | +4B | 0.058 | -0.094 | +0.071 | +-- | |||||||||||||
| Expert VLMs | -dots.ocr | -0.125 | -0.160 | -0.032 | -0.066 | -0.329 | -0.416 | -88.6 | -89.0 | -0.099 | -0.092 | -0.040 | -0.067 | -|||||
| MonkeyOCR-pro-3B | +3B | +0.075 | +0.128 | +- | +||||||||||||||
| MinerU2.5 | +1.2B | +0.047 | +0.044 | +- | +||||||||||||||
| PaddleOCR-VL | +0.9B | +0.035 | +0.043 | +9.51 | +||||||||||||||
| HunyuanOCR | +0.9B | +0.042 | +- | +- | +||||||||||||||
| PaddleOCR-VL1.5 | +0.9B | +0.035 | +0.042 | +- | +||||||||||||||
| GLMOCR | +0.9B | +0.04 | +0.043 | +- | +||||||||||||||
| dots.ocr | +3B | +0.048 | +0.053 | +9.29 | +||||||||||||||
| dots.ocr-1.5 | +3B | +0.031 | +0.029 | +9.54 | +
| Model Type |
-Models | -Book | -Slides | -Financial Report |
-Textbook | -Exam Paper |
-Magazine | -Academic Papers |
-Notes | -Newspaper | -Overall | -
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pipeline Tools |
-MinerU | -0.055 | -0.124 | -0.033 | -0.102 | -0.159 | -0.072 | -0.025 | -0.984 | -0.171 | -0.206 | -
| Marker | -0.074 | -0.340 | -0.089 | -0.319 | -0.452 | -0.153 | -0.059 | -0.651 | -0.192 | -0.274 | -|
| Mathpix | -0.131 | -0.220 | -0.202 | -0.216 | -0.278 | -0.147 | -0.091 | -0.634 | -0.690 | -0.300 | -|
| Expert VLMs |
-GOT-OCR | -0.111 | -0.222 | -0.067 | -0.132 | -0.204 | -0.198 | -0.179 | -0.388 | -0.771 | -0.267 | -
| Nougat | -0.734 | -0.958 | -1.000 | -0.820 | -0.930 | -0.830 | -0.214 | -0.991 | -0.871 | -0.806 | -|
| Dolphin | -0.091 | -0.131 | -0.057 | -0.146 | -0.231 | -0.121 | -0.074 | -0.363 | -0.307 | -0.177 | -|
| OCRFlux | -0.068 | -0.125 | -0.092 | -0.102 | -0.119 | -0.083 | -0.047 | -0.223 | -0.536 | -0.149 | -|
| MonkeyOCR-pro-3B | -0.084 | -0.129 | -0.060 | -0.090 | -0.107 | -0.073 | -0.050 | -0.171 | -0.107 | -0.100 | -|
| General VLMs |
-GPT4o | -0.157 | -0.163 | -0.348 | -0.187 | -0.281 | -0.173 | -0.146 | -0.607 | -0.751 | -0.316 | -
| Qwen2.5-VL-7B | -0.148 | -0.053 | -0.111 | -0.137 | -0.189 | -0.117 | -0.134 | -0.204 | -0.706 | -0.205 | -|
| InternVL3-8B | -0.163 | -0.056 | -0.107 | -0.109 | -0.129 | -0.100 | -0.159 | -0.150 | -0.681 | -0.188 | -|
| doubao-1-5-thinking-vision-pro-250428 | -0.048 | -0.048 | -0.024 | -0.062 | -0.085 | -0.051 | -0.039 | -0.096 | -0.181 | -0.073 | -|
| Expert VLMs | -dots.ocr | -0.031 | -0.047 | -0.011 | -0.082 | -0.079 | -0.028 | -0.029 | -0.109 | -0.056 | -0.055 | -
| Methods | -OverallEdit↓ | -TextEdit↓ | -FormulaEdit↓ | -TableTEDS↑ | -TableEdit↓ | -Read OrderEdit↓ | -MonkeyOCR-3B | -0.483 | -0.445 | -0.627 | -50.93 | -0.452 | -0.409 | - -
|---|---|---|---|---|---|---|
| doubao-1-5-thinking-vision-pro-250428 | -0.291 | -0.226 | -0.440 | -71.2 | -0.260 | -0.238 | -
| doubao-1-6 | -0.299 | -0.270 | -0.417 | -71.0 | -0.258 | -0.253 | -
| Gemini2.5-Pro | -0.251 | -0.163 | -0.402 | -77.1 | -0.236 | -0.202 | -
| dots.ocr | -0.177 | -0.075 | -0.297 | -79.2 | -0.186 | -0.152 | -
| Method | -F1@IoU=.50:.05:.95↑ | -F1@IoU=.50↑ | -||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Overall | -Text | -Formula | -Table | -Picture | -Overall | -Text | -Formula | -Table | -Picture | -DocLayout-YOLO-DocStructBench | -0.733 | -0.694 | -0.480 | -0.803 | -0.619 | -0.806 | -0.779 | -0.620 | -0.858 | -0.678 | - - -
| dots.ocr-parse all | -0.831 | -0.801 | -0.654 | -0.838 | -0.748 | -0.922 | -0.909 | -0.770 | -0.888 | -0.831 | -
| dots.ocr-detection only | -0.845 | -0.816 | -0.716 | -0.875 | -0.765 | -0.930 | -0.917 | -0.832 | -0.918 | -0.843 | -
| Model | -ArXiv | -Old Scans Math |
-Tables | -Old Scans | -Headers and Footers |
-Multi column |
-Long Tiny Text |
-Base | -Overall | -
|---|---|---|---|---|---|---|---|---|---|
| GOT OCR | -52.7 | -52.0 | -0.2 | -22.1 | -93.6 | -42.0 | -29.9 | -94.0 | -48.3 ± 1.1 | -
| Marker | -76.0 | -57.9 | -57.6 | -27.8 | -84.9 | -72.9 | -84.6 | -99.1 | -70.1 ± 1.1 | -
| MinerU | -75.4 | -47.4 | -60.9 | -17.3 | -96.6 | -59.0 | -39.1 | -96.6 | -61.5 ± 1.1 | -
| Mistral OCR | -77.2 | -67.5 | -60.6 | -29.3 | -93.6 | -71.3 | -77.1 | -99.4 | -72.0 ± 1.1 | -
| Nanonets OCR | -67.0 | -68.6 | -77.7 | -39.5 | -40.7 | -69.9 | -53.4 | -99.3 | -64.5 ± 1.1 | -
| GPT-4o (No Anchor) |
-51.5 | -75.5 | -69.1 | -40.9 | -94.2 | -68.9 | -54.1 | -96.7 | -68.9 ± 1.1 | -
| GPT-4o (Anchored) |
-53.5 | -74.5 | -70.0 | -40.7 | -93.8 | -69.3 | -60.6 | -96.8 | -69.9 ± 1.1 | -
| Gemini Flash 2 (No Anchor) |
-32.1 | -56.3 | -61.4 | -27.8 | -48.0 | -58.7 | -84.4 | -94.0 | -57.8 ± 1.1 | -
| Gemini Flash 2 (Anchored) |
-54.5 | -56.1 | -72.1 | -34.2 | -64.7 | -61.5 | -71.5 | -95.6 | -63.8 ± 1.2 | -
| Qwen 2 VL (No Anchor) |
-19.7 | -31.7 | -24.2 | -17.1 | -88.9 | -8.3 | -6.8 | -55.5 | -31.5 ± 0.9 | -
| Qwen 2.5 VL (No Anchor) |
-63.1 | -65.7 | -67.3 | -38.6 | -73.6 | -68.3 | -49.1 | -98.3 | -65.5 ± 1.2 | -
| olmOCR v0.1.75 (No Anchor) |
-71.5 | -71.4 | -71.4 | -42.8 | -94.1 | -77.7 | -71.0 | -97.8 | -74.7 ± 1.1 | -
| olmOCR v0.1.75 (Anchored) |
-74.9 | -71.2 | -71.0 | -42.2 | -94.5 | -78.3 | -73.3 | -98.3 | -75.5 ± 1.0 | -
| MonkeyOCR-pro-3B | -83.8 | -68.8 | -74.6 | -36.1 | -91.2 | -76.6 | -80.1 | -95.3 | -75.8 ± 1.0 | -
| dots.ocr | -82.1 | -64.2 | -88.3 | -40.9 | -94.1 | -82.4 | -81.2 | -99.5 | -79.1 ± 1.0 | -
| Methods | +Unisvg | +Chartmimic | +Design2Code | +Genexam | +SciGen | +ChemDraw | +|||
| Low-Level | +High-Level | +Score | +|||||||
| OCRVerse | +0.632 | +0.852 | +0.763 | +0.799 | +- | +- | +- | +0.881 | +|
| Gemini 3 Pro | +0.563 | +0.850 | +0.735 | +0.788 | +0.760 | +0.756 | +0.783 | +0.839 | +|
| dots.ocr-1.5 | +0.850 | +0.923 | +0.894 | +0.772 | +0.801 | +0.664 | +0.660 | +0.790 | +|
| dots.ocr-1.5-svg | +0.860 | +0.931 | +0.902 | +0.905 | +0.834 | +0.8 | +0.797 | +0.901 | +|
| Model | +CharXiv_descriptive | +CharXiv_reasoning | +OCR_Reasoning | +infovqa | +docvqa | +ChartQA | +OCRBench | +AI2D | +CountBenchQA | +refcoco | +
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3vl-2b-instruct | +62.3 | +26.8 | +- | +72.4 | +93.3 | +- | +85.8 | +76.9 | +88.4 | +- | +
| dots.ocr-1.5 | +77.4 | +55.3 | +22.85 | +73.76 | +91.85 | +83.2 | +86.0 | +82.16 | +94.46 | +80.03 | +
 -
- -
- -
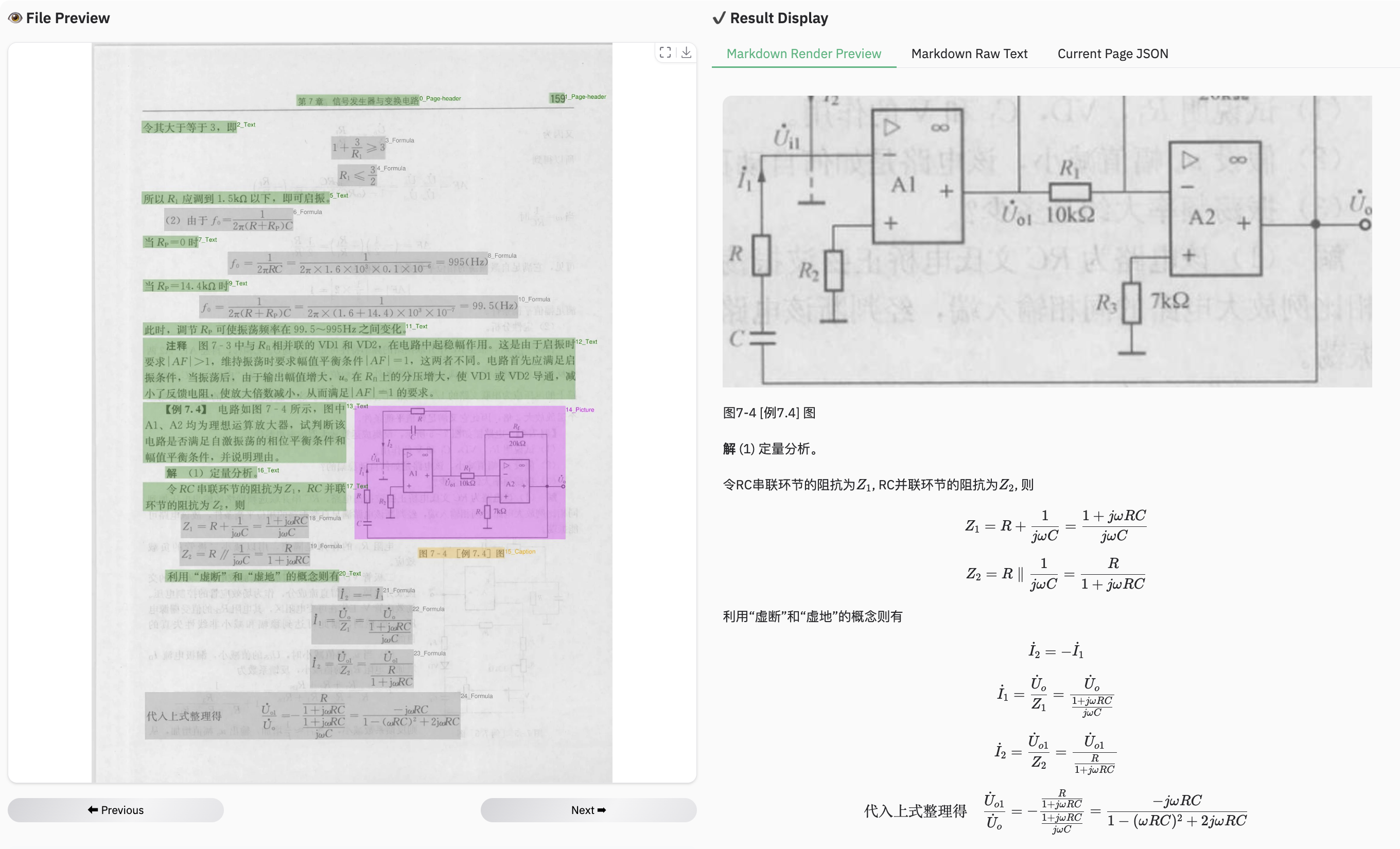
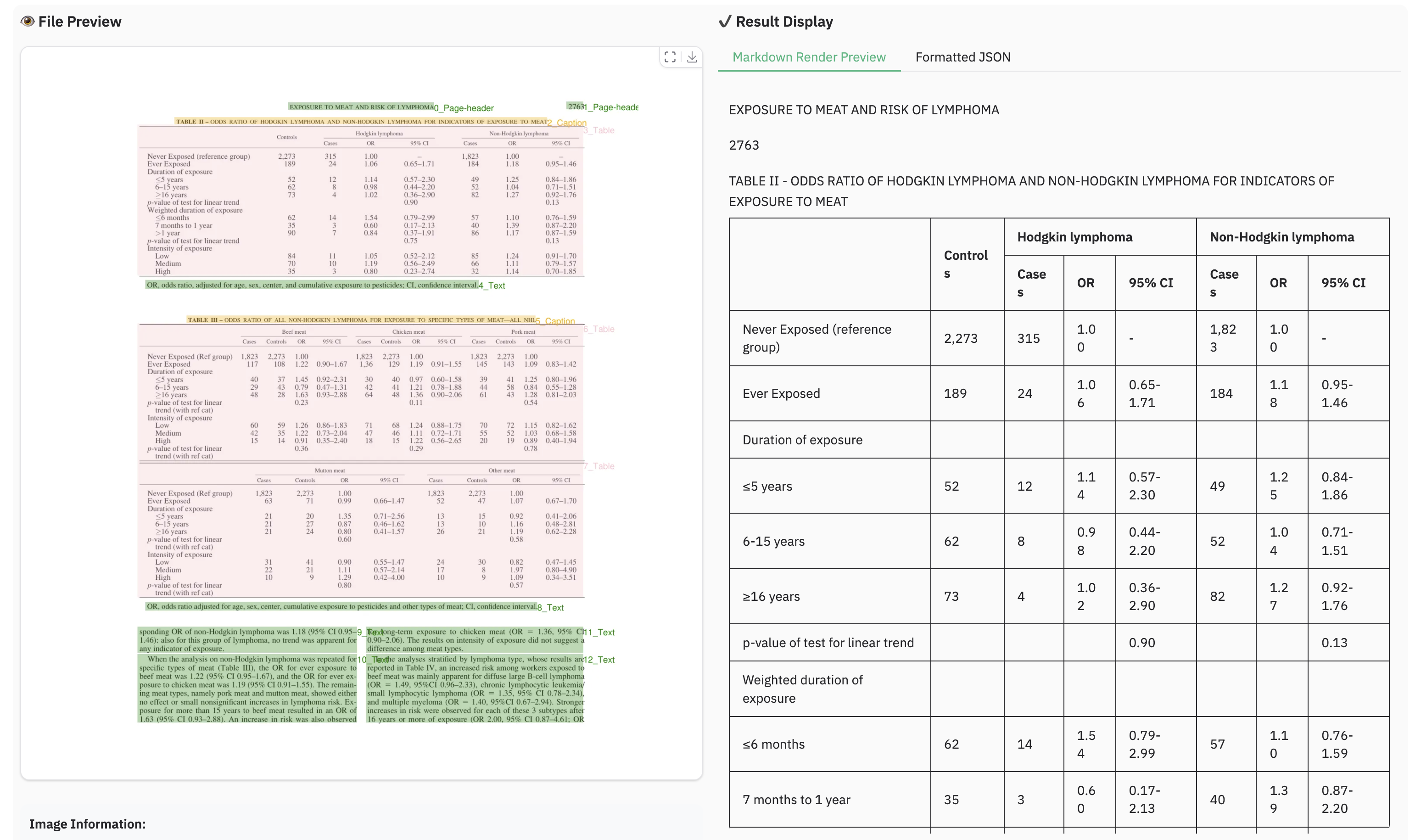
-### Example for table document
-
-
-### Example for table document
- -
-
 -
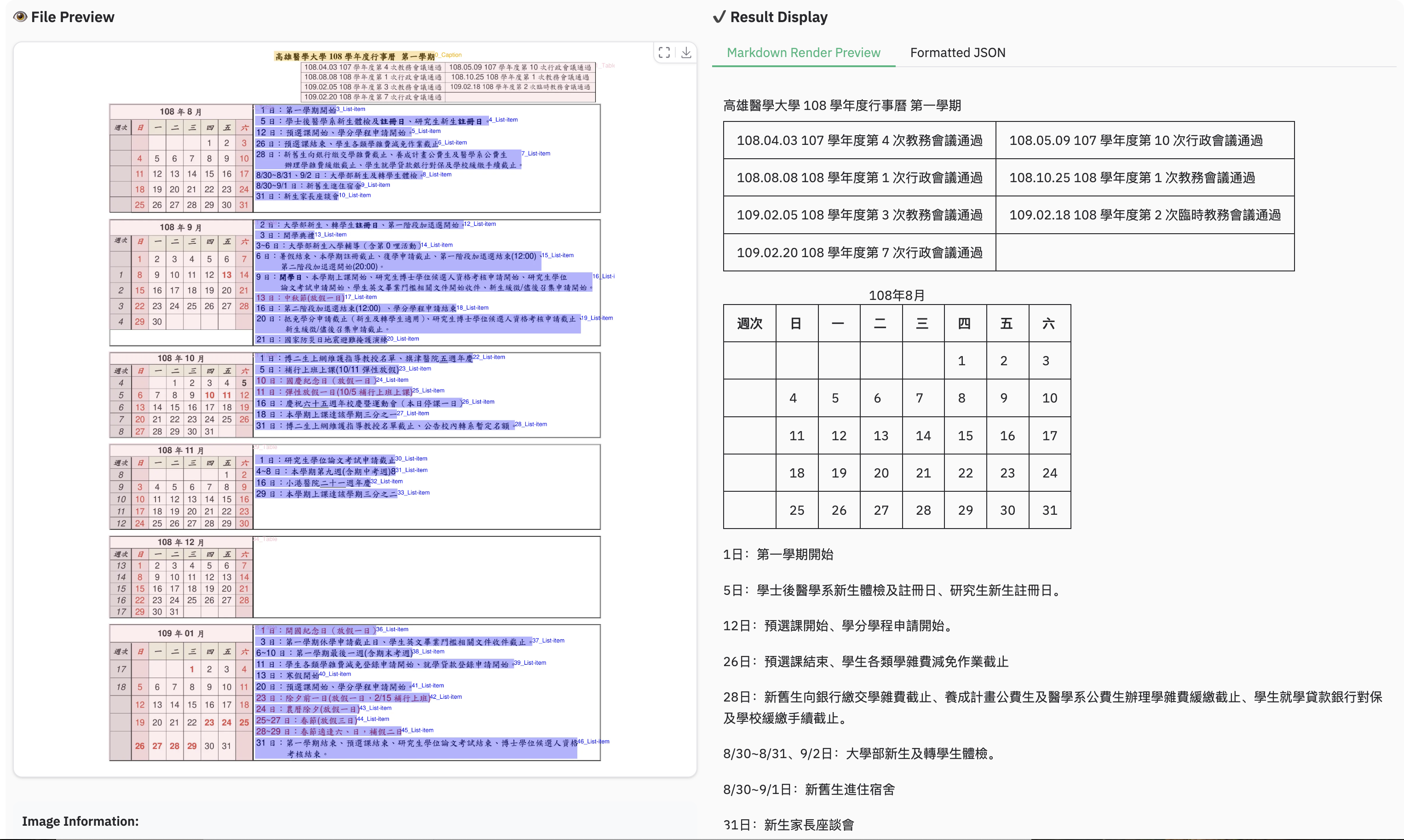
-### Example for multilingual document
-
-### Example for multilingual document




 -### Example for reading order
-
-### Example for reading order
- -### Example for grounding ocr
-
-### Example for grounding ocr
- +### Examples for image parsing
+
+### Examples for image parsing
+ +
+ +
+ +
+ +
+ +> **Note:**
+> - Inferenced by dots.ocr-1.5-svg
-# Acknowledgments
-We would like to thank [Qwen2.5-VL](https://github.com/QwenLM/Qwen2.5-VL), [aimv2](https://github.com/apple/ml-aim), [MonkeyOCR](https://github.com/Yuliang-Liu/MonkeyOCR),
-[OmniDocBench](https://github.com/opendatalab/OmniDocBench), [PyMuPDF](https://github.com/pymupdf/PyMuPDF), for providing code and models.
+### Example for web parsing
+
+> **Note:**
+> - Inferenced by dots.ocr-1.5-svg
-# Acknowledgments
-We would like to thank [Qwen2.5-VL](https://github.com/QwenLM/Qwen2.5-VL), [aimv2](https://github.com/apple/ml-aim), [MonkeyOCR](https://github.com/Yuliang-Liu/MonkeyOCR),
-[OmniDocBench](https://github.com/opendatalab/OmniDocBench), [PyMuPDF](https://github.com/pymupdf/PyMuPDF), for providing code and models.
+### Example for web parsing
+ +
+ +
+### Examples for scene spotting
+
+
+### Examples for scene spotting
+ +
+ -We also thank [DocLayNet](https://github.com/DS4SD/DocLayNet), [M6Doc](https://github.com/HCIILAB/M6Doc), [CDLA](https://github.com/buptlihang/CDLA), [D4LA](https://github.com/AlibabaResearch/AdvancedLiterateMachinery) for providing valuable datasets.
# Limitation & Future Work
- **Complex Document Elements:**
- - **Table&Formula**: dots.ocr is not yet perfect for high-complexity tables and formula extraction.
- - **Picture**: Pictures in documents are currently not parsed.
+ - **Table&Formula**: The extraction of complex tables and mathematical formulas persists as a difficult task given the model's compact architecture.
+ - **Picture**: We have adopted an SVG code representation for parsing structured graphics; however, the performance has yet to achieve the desired level of robustness.
-- **Parsing Failures:** The model may fail to parse under certain conditions:
- - When the character-to-pixel ratio is excessively high. Try enlarging the image or increasing the PDF parsing DPI (a setting of 200 is recommended). However, please note that the model performs optimally on images with a resolution under 11289600 pixels.
- - Continuous special characters, such as ellipses (`...`) and underscores (`_`), may cause the prediction output to repeat endlessly. In such scenarios, consider using alternative prompts like `prompt_layout_only_en`, `prompt_ocr`, or `prompt_grounding_ocr` ([details here](https://github.com/rednote-hilab/dots.ocr/blob/master/dots_ocr/utils/prompts.py)).
-
-- **Performance Bottleneck:** Despite its 1.7B parameter LLM foundation, **dots.ocr** is not yet optimized for high-throughput processing of large PDF volumes.
+- **Parsing Failures:** While we have reduced the rate of parsing failures compared to the previous version, these issues may still occur occasionally. We remain committed to further resolving these edge cases in future updates.
-We are committed to achieving more accurate table and formula parsing, as well as enhancing the model's OCR capabilities for broader generalization, all while aiming for **a more powerful, more efficient model**. Furthermore, we are actively considering the development of **a more general-purpose perception model** based on Vision-Language Models (VLMs), which would integrate general detection, image captioning, and OCR tasks into a unified framework. **Parsing the content of the pictures in the documents** is also a key priority for our future work.
-We believe that collaboration is the key to tackling these exciting challenges. If you are passionate about advancing the frontiers of document intelligence and are interested in contributing to these future endeavors, we would love to hear from you. Please reach out to us via email at: [yanqing4@xiaohongshu.com].
# Citation
diff --git a/README_hf.md b/README_hf.md
new file mode 100755
index 0000000..a43b508
--- /dev/null
+++ b/README_hf.md
@@ -0,0 +1,778 @@
+---
+license: mit
+library_name: dots_ocr_1_5
+pipeline_tag: image-text-to-text
+tags:
+- image-to-text
+- ocr
+- document-parse
+- layout
+- table
+- formula
+- transformers
+- custom_code
+language:
+- en
+- zh
+- multilingual
+---
+
+
-We also thank [DocLayNet](https://github.com/DS4SD/DocLayNet), [M6Doc](https://github.com/HCIILAB/M6Doc), [CDLA](https://github.com/buptlihang/CDLA), [D4LA](https://github.com/AlibabaResearch/AdvancedLiterateMachinery) for providing valuable datasets.
# Limitation & Future Work
- **Complex Document Elements:**
- - **Table&Formula**: dots.ocr is not yet perfect for high-complexity tables and formula extraction.
- - **Picture**: Pictures in documents are currently not parsed.
+ - **Table&Formula**: The extraction of complex tables and mathematical formulas persists as a difficult task given the model's compact architecture.
+ - **Picture**: We have adopted an SVG code representation for parsing structured graphics; however, the performance has yet to achieve the desired level of robustness.
-- **Parsing Failures:** The model may fail to parse under certain conditions:
- - When the character-to-pixel ratio is excessively high. Try enlarging the image or increasing the PDF parsing DPI (a setting of 200 is recommended). However, please note that the model performs optimally on images with a resolution under 11289600 pixels.
- - Continuous special characters, such as ellipses (`...`) and underscores (`_`), may cause the prediction output to repeat endlessly. In such scenarios, consider using alternative prompts like `prompt_layout_only_en`, `prompt_ocr`, or `prompt_grounding_ocr` ([details here](https://github.com/rednote-hilab/dots.ocr/blob/master/dots_ocr/utils/prompts.py)).
-
-- **Performance Bottleneck:** Despite its 1.7B parameter LLM foundation, **dots.ocr** is not yet optimized for high-throughput processing of large PDF volumes.
+- **Parsing Failures:** While we have reduced the rate of parsing failures compared to the previous version, these issues may still occur occasionally. We remain committed to further resolving these edge cases in future updates.
-We are committed to achieving more accurate table and formula parsing, as well as enhancing the model's OCR capabilities for broader generalization, all while aiming for **a more powerful, more efficient model**. Furthermore, we are actively considering the development of **a more general-purpose perception model** based on Vision-Language Models (VLMs), which would integrate general detection, image captioning, and OCR tasks into a unified framework. **Parsing the content of the pictures in the documents** is also a key priority for our future work.
-We believe that collaboration is the key to tackling these exciting challenges. If you are passionate about advancing the frontiers of document intelligence and are interested in contributing to these future endeavors, we would love to hear from you. Please reach out to us via email at: [yanqing4@xiaohongshu.com].
# Citation
diff --git a/README_hf.md b/README_hf.md
new file mode 100755
index 0000000..a43b508
--- /dev/null
+++ b/README_hf.md
@@ -0,0 +1,778 @@
+---
+license: mit
+library_name: dots_ocr_1_5
+pipeline_tag: image-text-to-text
+tags:
+- image-to-text
+- ocr
+- document-parse
+- layout
+- table
+- formula
+- transformers
+- custom_code
+language:
+- en
+- zh
+- multilingual
+---
+
+
+ ![]() +
+
+ +
| models | +olmOCR-Bench | +OmniDocBench (v1.5) | +XDocParse | +
|---|---|---|---|
| GLM-OCR | +859.9 | +937.5 | +742.1 | +
| PaddleOCR-VL-1.5 | +873.6 | +965.6 | +797.6 | +
| HuanyuanOCR | +978.9 | +974.4 | +895.9 | +
| dots.ocr | +1027.4 | +994.7 | +1133.4 | +
| dots.ocr-1.5 | +1089.0 | +1025.8 | +1157.1 | +
| Gemini 3 Pro | +1171.2 | +1102.1 | +1273.9 | +
| + | ArXiv | +Old scans math | +Tables | +Old scans | +Headers & footers | +Multi column | +Long tiny text | +Base | +Overall | +
|---|---|---|---|---|---|---|---|---|---|
| Mistral OCR API | +77.2 | +67.5 | +60.6 | +29.3 | +93.6 | +71.3 | +77.1 | +99.4 | +72.0±1.1 | +
| Marker 1.10.1 | +83.8 | +66.8 | +72.9 | +33.5 | +86.6 | +80.0 | +85.7 | +99.3 | +76.1±1.1 | +
| MinerU 2.5.4* | +76.6 | +54.6 | +84.9 | +33.7 | +96.6 | +78.2 | +83.5 | +93.7 | +75.2±1.1 | +
| DeepSeek-OCR | +77.2 | +73.6 | +80.2 | +33.3 | +96.1 | +66.4 | +79.4 | +99.8 | +75.7±1.0 | +
| Nanonets-OCR2-3B | +75.4 | +46.1 | +86.8 | +40.9 | +32.1 | +81.9 | +93.0 | +99.6 | +69.5±1.1 | +
| PaddleOCR-VL* | +85.7 | +71.0 | +84.1 | +37.8 | +97.0 | +79.9 | +85.7 | +98.5 | +80.0±1.0 | +
| Infinity-Parser 7B* | +84.4 | +83.8 | +85.0 | +47.9 | +88.7 | +84.2 | +86.4 | +99.8 | +82.5±? | +
| olmOCR v0.4.0 | +83.0 | +82.3 | +84.9 | +47.7 | +96.1 | +83.7 | +81.9 | +99.7 | +82.4±1.1 | +
| Chandra OCR 0.1.0* | +82.2 | +80.3 | +88.0 | +50.4 | +90.8 | +81.2 | +92.3 | +99.9 | +83.1±0.9 | +
| dots.ocr | +82.1 | +64.2 | +88.3 | +40.9 | +94.1 | +82.4 | +81.2 | +99.5 | +79.1% ± 1.0% | +
| dots.ocr-1.5 | +85.9 | +85.5 | +90.7 | +48.2 | +94.0 | +85.3 | +81.6 | +99.7 | +83.9% ± 0.9 | +
| Model Type | +Methods | +Size | +OmniDocBench(v1.5) TextEdit↓ |
+ OmniDocBench(v1.5) Read OrderEdit↓ |
+ pdf-parse-bench | +
|---|---|---|---|---|---|
| GeneralVLMs | +Gemini-2.5 Pro | +- | +0.075 | +0.097 | +9.06 | +
| Qwen3-VL-235B-A22B-Instruct | +235B | +0.069 | +0.068 | +9.71 | +|
| gemini3pro | +- | +0.066 | +0.079 | +9.68 | +|
| SpecializedVLMs | +Mistral OCR | +- | +0.164 | +0.144 | +8.84 | +
| Deepseek-OCR | +3B | +0.073 | +0.086 | +8.26 | +|
| MonkeyOCR-3B | +3B | +0.075 | +0.129 | +9.27 | +|
| OCRVerse | +4B | +0.058 | +0.071 | +-- | +|
| MonkeyOCR-pro-3B | +3B | +0.075 | +0.128 | +- | +|
| MinerU2.5 | +1.2B | +0.047 | +0.044 | +- | +|
| PaddleOCR-VL | +0.9B | +0.035 | +0.043 | +9.51 | +|
| HunyuanOCR | +0.9B | +0.042 | +- | +- | +|
| PaddleOCR-VL1.5 | +0.9B | +0.035 | +0.042 | +- | +|
| GLMOCR | +0.9B | +0.04 | +0.043 | +- | +|
| dots.ocr | +3B | +0.048 | +0.053 | +9.29 | +|
| dots.ocr-1.5 | +3B | +0.031 | +0.029 | +9.54 | +
| Methods | +Unisvg | +Chartmimic | +Design2Code | +Genexam | +SciGen | +ChemDraw | +||
|---|---|---|---|---|---|---|---|---|
| Low-Level | +High-Level | +Score | +||||||
| OCRVerse | +0.632 | +0.852 | +0.763 | +0.799 | +- | +- | +- | +0.881 | +
| Gemini 3 Pro | +0.563 | +0.850 | +0.735 | +0.788 | +0.760 | +0.756 | +0.783 | +0.839 | +
| dots.ocr-1.5 | +0.850 | +0.923 | +0.894 | +0.772 | +0.801 | +0.664 | +0.660 | +0.790 | +
| dots.ocr-1.5-svg | +0.860 | +0.931 | +0.902 | +0.905 | +0.834 | +0.8 | +0.797 | +0.901 | +
| Model | +CharXiv_descriptive | +CharXiv_reasoning | +OCR_Reasoning | +infovqa | +docvqa | +ChartQA | +OCRBench | +AI2D | +CountBenchQA | +refcoco | +
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3vl-2b-instruct | +62.3 | +26.8 | +- | +72.4 | +93.3 | +- | +85.8 | +76.9 | +88.4 | +- | +
| dots.ocr-1.5 | +77.4 | +55.3 | +22.85 | +73.76 | +91.85 | +83.2 | +86.0 | +82.16 | +94.46 | +80.03 | +
+
+
+
+
+
+
+
+
+### Examples for image parsing
+
+
+
+
+
+
+> **Note:**
+> - Inferenced by dots.ocr-1.5-svg
+
+### Example for web parsing
+
+
+
+### Examples for scene spotting
+
+
+
+
+
+## Limitation & Future Work
+
+- **Complex Document Elements:**
+ - **Table&Formula**: The extraction of complex tables and mathematical formulas persists as a difficult task given the model's compact architecture.
+ - **Picture**: We have adopted an SVG code representation for parsing structured graphics; however, the performance has yet to achieve the desired level of robustness.
+
+- **Parsing Failures:** While we have reduced the rate of parsing failures compared to the previous version, these issues may still occur occasionally. We remain committed to further resolving these edge cases in future updates.
\ No newline at end of file
diff --git a/assets/showcase_dots_ocr_1_5/result/scene_1.png b/assets/showcase_dots_ocr_1_5/result/scene_1.png
new file mode 100644
index 0000000..f5f3a57
Binary files /dev/null and b/assets/showcase_dots_ocr_1_5/result/scene_1.png differ
diff --git a/assets/showcase_dots_ocr_1_5/result/scene_2.png b/assets/showcase_dots_ocr_1_5/result/scene_2.png
new file mode 100644
index 0000000..a8031c6
Binary files /dev/null and b/assets/showcase_dots_ocr_1_5/result/scene_2.png differ
diff --git a/assets/showcase_dots_ocr_1_5/result/svg_1.png b/assets/showcase_dots_ocr_1_5/result/svg_1.png
new file mode 100644
index 0000000..5b8c1f3
Binary files /dev/null and b/assets/showcase_dots_ocr_1_5/result/svg_1.png differ
diff --git a/assets/showcase_dots_ocr_1_5/result/svg_2.png b/assets/showcase_dots_ocr_1_5/result/svg_2.png
new file mode 100644
index 0000000..65b64a7
Binary files /dev/null and b/assets/showcase_dots_ocr_1_5/result/svg_2.png differ
diff --git a/assets/showcase_dots_ocr_1_5/result/svg_4.png b/assets/showcase_dots_ocr_1_5/result/svg_4.png
new file mode 100644
index 0000000..c458456
Binary files /dev/null and b/assets/showcase_dots_ocr_1_5/result/svg_4.png differ
diff --git a/assets/showcase_dots_ocr_1_5/result/svg_5.png b/assets/showcase_dots_ocr_1_5/result/svg_5.png
new file mode 100644
index 0000000..fe8d103
Binary files /dev/null and b/assets/showcase_dots_ocr_1_5/result/svg_5.png differ
diff --git a/assets/showcase_dots_ocr_1_5/result/svg_6.png b/assets/showcase_dots_ocr_1_5/result/svg_6.png
new file mode 100644
index 0000000..803fcd4
Binary files /dev/null and b/assets/showcase_dots_ocr_1_5/result/svg_6.png differ
diff --git a/assets/showcase_dots_ocr_1_5/result/webpage_1.png b/assets/showcase_dots_ocr_1_5/result/webpage_1.png
new file mode 100644
index 0000000..d2c9042
Binary files /dev/null and b/assets/showcase_dots_ocr_1_5/result/webpage_1.png differ
diff --git a/assets/showcase_dots_ocr_1_5/result/webpage_2.png b/assets/showcase_dots_ocr_1_5/result/webpage_2.png
new file mode 100644
index 0000000..a7da568
Binary files /dev/null and b/assets/showcase_dots_ocr_1_5/result/webpage_2.png differ
diff --git a/requirements.txt b/requirements.txt
index 7eed6f1..15852ca 100755
--- a/requirements.txt
+++ b/requirements.txt
@@ -7,5 +7,6 @@ qwen_vl_utils
transformers==4.51.3
huggingface_hub
modelscope
-flash-attn==2.8.0.post2
+# flash-attn==2.8.0.post2 # to speed up inference need flash-attn
accelerate
+cairosvg
\ No newline at end of file
diff --git a/tools/download_model.py b/tools/download_model.py
index 32d7087..d5db841 100755
--- a/tools/download_model.py
+++ b/tools/download_model.py
@@ -5,11 +5,11 @@ import os
if __name__ == '__main__':
parser = ArgumentParser()
parser.add_argument('--type', '-t', type=str, default="huggingface")
- parser.add_argument('--name', '-n', type=str, default="rednote-hilab/dots.ocr")
+ parser.add_argument('--name', '-n', type=str, default="rednote-hilab/dots.ocr-1.5")
args = parser.parse_args()
script_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
print(f"Attention: The model save dir dots.ocr should be replace by a name without `.` like DotsOCR, util we merge our code to transformers.")
- model_dir = os.path.join(script_dir, "weights/DotsOCR")
+ model_dir = os.path.join(script_dir, "weights/DotsOCR_1_5")
if not os.path.exists(model_dir):
os.makedirs(model_dir)
if args.type == "huggingface":
diff --git a/tools/elo_score_prompt.py b/tools/elo_score_prompt.py
new file mode 100644
index 0000000..c8b5e06
--- /dev/null
+++ b/tools/elo_score_prompt.py
@@ -0,0 +1,89 @@
+def construct_prompt(c1_text, c2_text):
+ """
+ Constructs the complete Prompt sent to Gemini (English Version).
+ c1_text: Markdown text from Model 1
+ c2_text: Markdown text from Model 2
+ """
+
+ prompt = f"""You are an expert in evaluating OCR content accuracy. Please compare the model outputs with the original image, focusing heavily on **content accuracy** while ignoring formatting and layout differences.
+
+【Evaluation Focus - Focus ONLY on Content Accuracy】
+1. **Text Accuracy**:
+ - Typos: Character recognition errors (e.g., "test" recognized as "tost").
+ - Omissions: Missing characters or words present in the original text.
+ - Hallucinations: Adding characters that do not exist in the original text.
+
+2. **Table Accuracy**:
+ - Correctness of data and text within the table.
+ - Completeness of cell content.
+ - Correct row/column alignment.
+
+3. **Formula Accuracy** (Evaluate based on):
+ - **Correctness**: Are mathematical symbols, variables, and operators preserved accurately?
+ - **Completeness**: Are all parts of the formula present without omission?
+ - **Semantic Equivalence**: Does the extracted formula convey the exact same mathematical meaning?
+
+【Tie Judgment Criteria - Important】
+You must judge as a **tie** in the following cases:
+- Text content is identical, differing only in Markdown formatting.
+- Table data is identical, differing only in Markdown table syntax.
+- Formula content is semantically equivalent, differing only in LaTeX representation.
+- Both models correctly identified the core content; minor differences do not affect information retrieval.
+- Both models share the same minor errors or are both perfect.
+- **Image/Figure processing differs** (one extracts text, one gives bbox, one ignores it), but the main text is accurate.
+
+【Items to Ignore - Do NOT factor into scoring】
+- Markdown formatting differences (e.g., `# Header` vs `## Header`, `*` vs `-` for lists).
+- Layout and typesetting differences (newlines, indentation, alignment).
+- Recognition differences in non-body text like Headers, Footers, and Page Numbers.
+- Text wrapping and paragraph segmentation nuances.
+- Table border styles (e.g., `|---|---|` vs `|:--|--:|`).
+- Different but equivalent LaTeX representations for formulas.
+- **Image/Figure Processing Differences (ABSOLUTELY IGNORE)**:
+ - How the model parses image/figure regions is **completely excluded** from the scoring standard.
+ - Whether it parses as a `figure` field, outputs bbox coordinates, extracts text inside the image, provides a caption, describes the image content, or **completely ignores/skips the image**, these are all considered equivalent.
+ - Do NOT declare a winner based on image handling.
+
+【Model 1 Output】:
+```markdown
+{c1_text}
+```
+
+【Model 2 Output】:
+```markdown
+{c2_text}
+```
+
+【Evaluation Process】
+1. Carefully compare the text content against the original image.
+2. Identify errors, omissions, or additions in text recognition for both models.
+3. Check the accuracy of table data.
+4. Evaluate the correctness, completeness, and semantic equivalence of mathematical formulas.
+5. **Ignore image regions**: Confirm that differences in image/figure parsing are not used for scoring.
+6. Important: If the substance is the same and only the format differs, judge as a tie.
+7. Only declare a winner if there is a significant difference in **content accuracy**.
+
+【Examples of Ties】
+- Model 1: "# Title", Model 2: "## Title" (Same content, different level).
+- Model 1: "* Item", Model 2: "- Item" (Same content, different bullet).
+- Formula: Model 1 "$x^2$", Model 2 "$x*x$" (Different LaTeX, same meaning).
+- Table data is identical, but column alignment syntax differs.
+- Identification is identical, but one model parsed the footer while the other didn't (Judge as Tie).
+- **Image handling**: Model 1 outputs an image bbox, Model 2 outputs an image description, Model 3 ignores the image. As long as the main text is accurate, this is a **Tie**.
+
+【Output Requirement】 Please strictly return the result in the following JSON format:
+
+{{"winner": "tie", "reason": "Detailed explanation of the judgment, specifically noting the logic for a tie"}}
+
+The value of "winner" must be one of:
+- "1": Model 1 is clearly better in content accuracy.
+- "2": Model 2 is clearly better in content accuracy.
+- "tie": Both models perform equally in content accuracy (including cases of identical content but different formatting/image handling).
+
+In the "reason" field, specifically explain:
+- If a tie: Explain the consistency of the content and explicitly mention which formatting or image handling differences were ignored.
+- If a winner: Specifically point out the accuracy differences (typos, missing words, table/formula errors).
+- **Note**: It is better to judge a tie than to incorrectly determine a winner based on minor formatting or image parsing differences. **Content accuracy of the main text is the ONLY standard.**
+"""
+
+ return prompt
\ No newline at end of file