![]()
![]()
| models | olmOCR-Bench | OmniDocBench (v1.5) | XDocParse |
|---|---|---|---|
| GLM-OCR | 859.9 | 937.5 | 742.1 |
| PaddleOCR-VL-1.5 | 873.6 | 965.6 | 797.6 |
| HuanyuanOCR | 978.9 | 974.4 | 895.9 |
| dots.ocr | 1027.4 | 994.7 | 1133.4 |
| dots.ocr-1.5 | 1089.0 | 1025.8 | 1157.1 |
| Gemini 3 Pro | 1171.2 | 1102.1 | 1273.9 |
| Model | ArXiv | Old scans math | Tables | Old scans | Headers & footers | Multi column | Long tiny text | Base | Overall |
|---|---|---|---|---|---|---|---|---|---|
| Mistral OCR API | 77.2 | 67.5 | 60.6 | 29.3 | 93.6 | 71.3 | 77.1 | 99.4 | 72.0±1.1 |
| Marker 1.10.1 | 83.8 | 66.8 | 72.9 | 33.5 | 86.6 | 80.0 | 85.7 | 99.3 | 76.1±1.1 |
| MinerU 2.5.4* | 76.6 | 54.6 | 84.9 | 33.7 | 96.6 | 78.2 | 83.5 | 93.7 | 75.2±1.1 |
| DeepSeek-OCR | 77.2 | 73.6 | 80.2 | 33.3 | 96.1 | 66.4 | 79.4 | 99.8 | 75.7±1.0 |
| Nanonets-OCR2-3B | 75.4 | 46.1 | 86.8 | 40.9 | 32.1 | 81.9 | 93.0 | 99.6 | 69.5±1.1 |
| PaddleOCR-VL* | 85.7 | 71.0 | 84.1 | 37.8 | 97.0 | 79.9 | 85.7 | 98.5 | 80.0±1.0 |
| Infinity-Parser 7B* | 84.4 | 83.8 | 85.0 | 47.9 | 88.7 | 84.2 | 86.4 | 99.8 | 82.5±? |
| olmOCR v0.4.0 | 83.0 | 82.3 | 84.9 | 47.7 | 96.1 | 83.7 | 81.9 | 99.7 | 82.4±1.1 |
| Chandra OCR 0.1.0* | 82.2 | 80.3 | 88.0 | 50.4 | 90.8 | 81.2 | 92.3 | 99.9 | 83.1±0.9 |
| dots.ocr | 82.1 | 64.2 | 88.3 | 40.9 | 94.1 | 82.4 | 81.2 | 99.5 | 79.1±1.0 |
| dots.ocr-1.5 | 85.9 | 85.5 | 90.7 | 48.2 | 94.0 | 85.3 | 81.6 | 99.7 | 83.9±0.9 |
| Model Type | Methods | Size | OmniDocBench(v1.5) TextEdit↓ |
OmniDocBench(v1.5) Read OrderEdit↓ |
pdf-parse-bench |
|---|---|---|---|---|---|
| GeneralVLMs | Gemini-2.5 Pro | - | 0.075 | 0.097 | 9.06 |
| Qwen3-VL-235B-A22B-Instruct | 235B | 0.069 | 0.068 | 9.71 | |
| gemini3pro | - | 0.066 | 0.079 | 9.68 | |
| SpecializedVLMs | Mistral OCR | - | 0.164 | 0.144 | 8.84 |
| Deepseek-OCR | 3B | 0.073 | 0.086 | 8.26 | |
| MonkeyOCR-3B | 3B | 0.075 | 0.129 | 9.27 | |
| OCRVerse | 4B | 0.058 | 0.071 | -- | |
| MonkeyOCR-pro-3B | 3B | 0.075 | 0.128 | - | |
| MinerU2.5 | 1.2B | 0.047 | 0.044 | - | |
| PaddleOCR-VL | 0.9B | 0.035 | 0.043 | 9.51 | |
| HunyuanOCR | 0.9B | 0.042 | - | - | |
| PaddleOCR-VL1.5 | 0.9B | 0.035 | 0.042 | - | |
| GLMOCR | 0.9B | 0.04 | 0.043 | - | |
| dots.ocr | 3B | 0.048 | 0.053 | 9.29 | |
| dots.ocr-1.5 | 3B | 0.031 | 0.029 | 9.54 |
| Methods | Unisvg | Chartmimic | Design2Code | Genexam | SciGen | ChemDraw | ||
|---|---|---|---|---|---|---|---|---|
| Low-Level | High-Level | Score | ||||||
| OCRVerse | 0.632 | 0.852 | 0.763 | 0.799 | - | - | - | 0.881 |
| Gemini 3 Pro | 0.563 | 0.850 | 0.735 | 0.788 | 0.760 | 0.756 | 0.783 | 0.839 |
| dots.ocr-1.5 | 0.850 | 0.923 | 0.894 | 0.772 | 0.801 | 0.664 | 0.660 | 0.790 |
| dots.ocr-1.5-svg | 0.860 | 0.931 | 0.902 | 0.905 | 0.834 | 0.8 | 0.797 | 0.901 |
| Model | CharXiv_descriptive | CharXiv_reasoning | OCR_Reasoning | infovqa | docvqa | ChartQA | OCRBench | AI2D | CountBenchQA | refcoco |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3vl-2b-instruct | 62.3 | 26.8 | - | 72.4 | 93.3 | - | 85.8 | 76.9 | 88.4 | - |
| dots.ocr-1.5 | 77.4 | 55.3 | 22.85 | 73.76 | 91.85 | 83.2 | 86.0 | 82.16 | 94.46 | 80.03 |

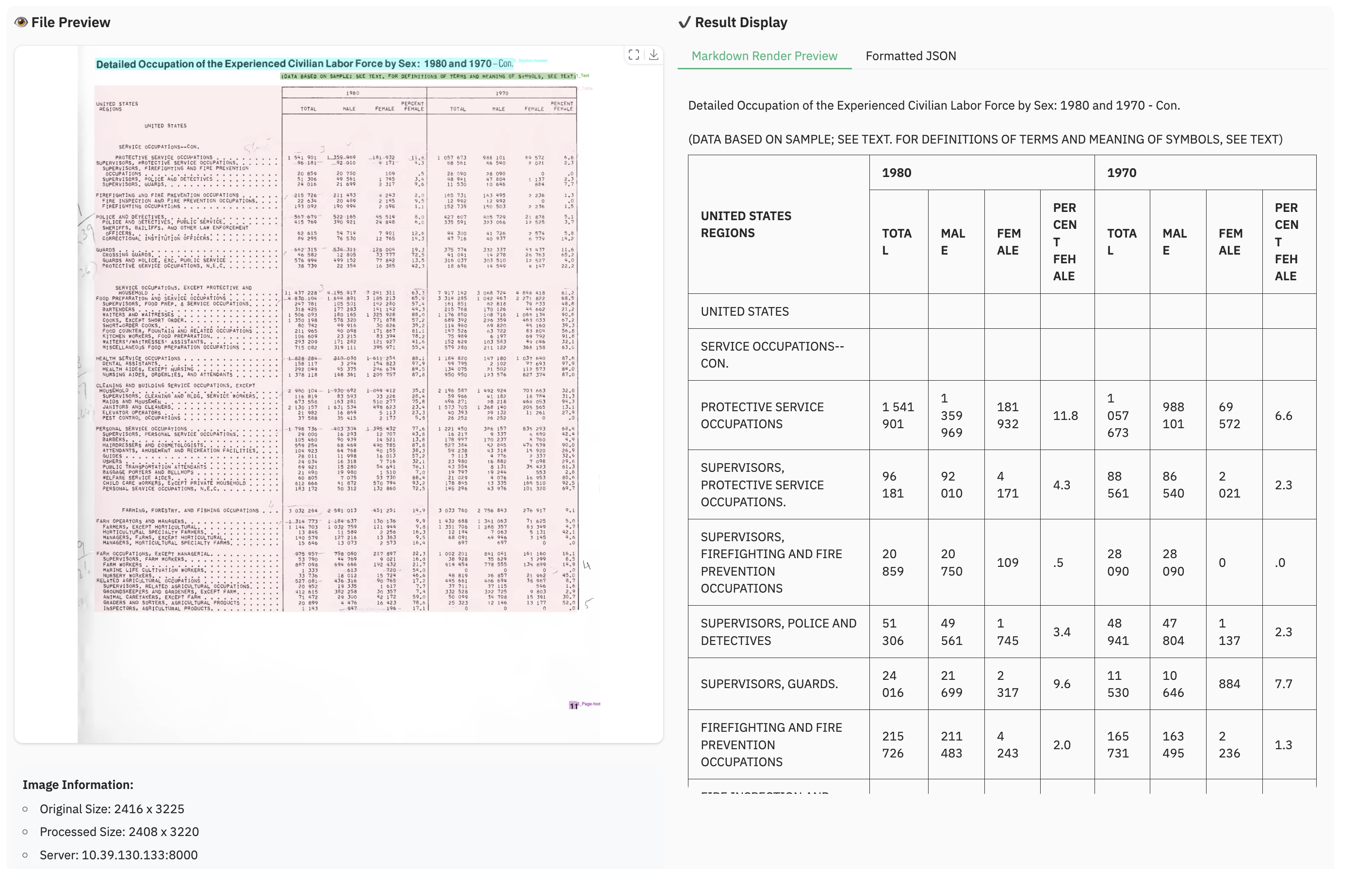




 ### Examples for image parsing
### Examples for image parsing
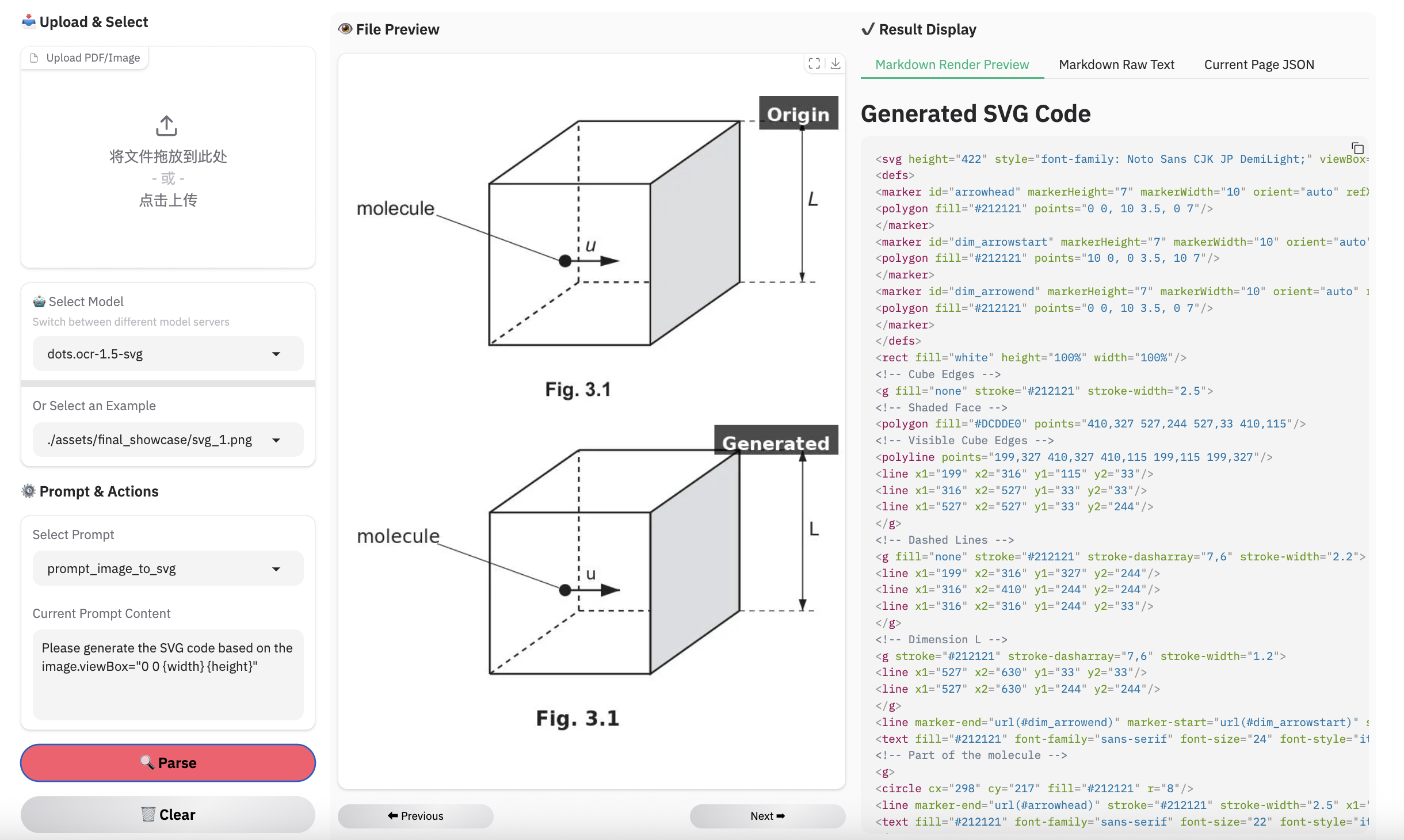
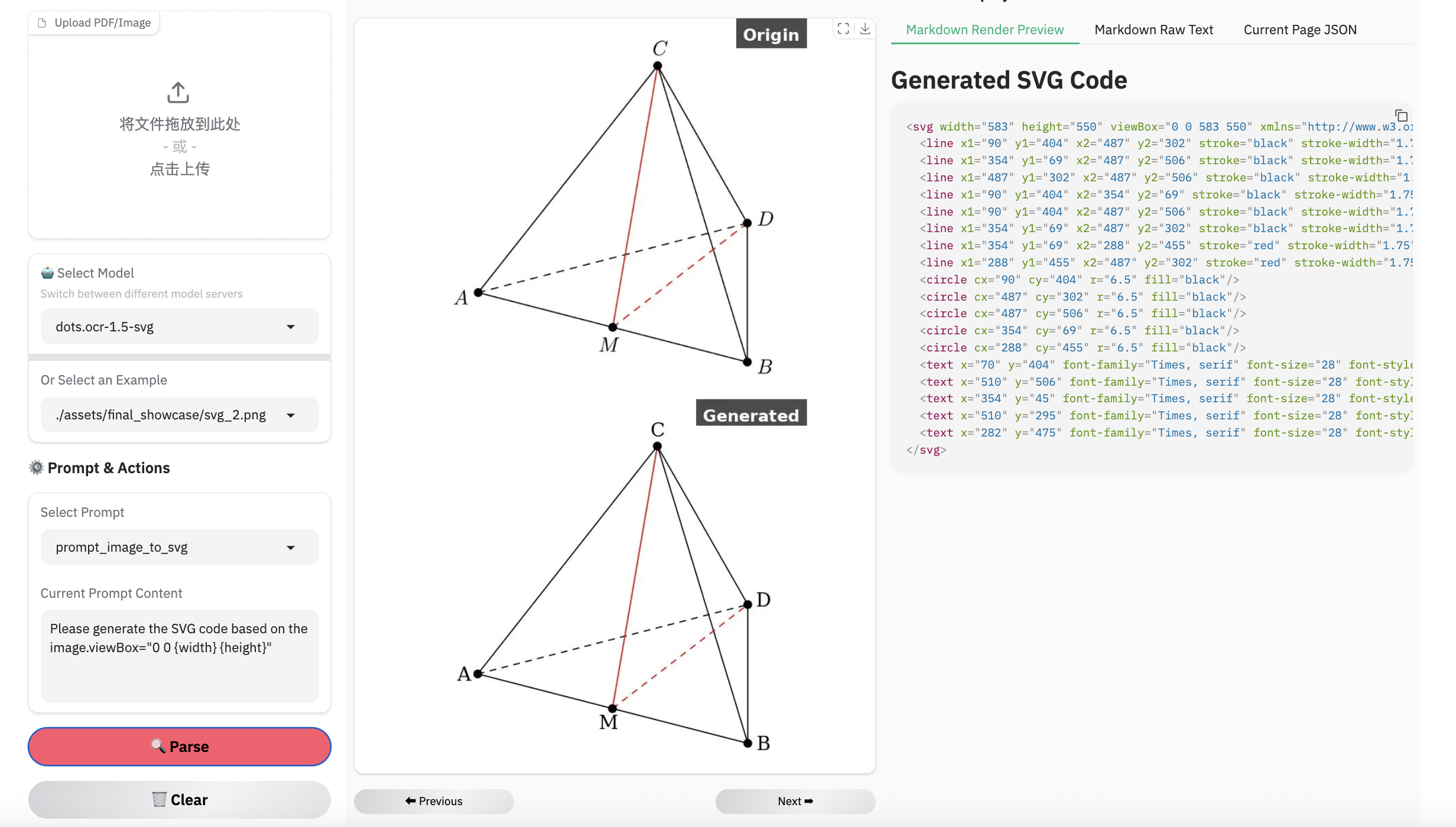
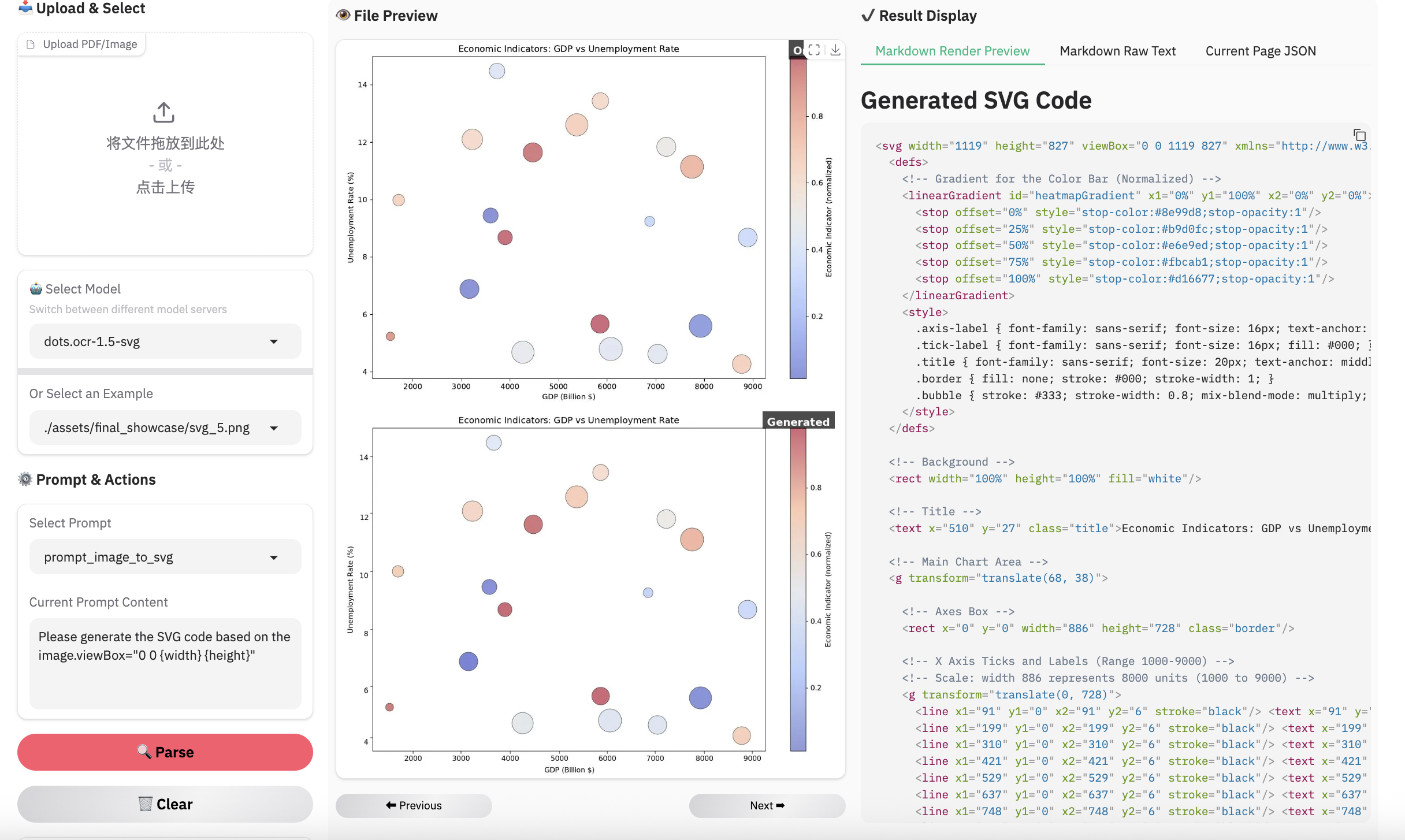
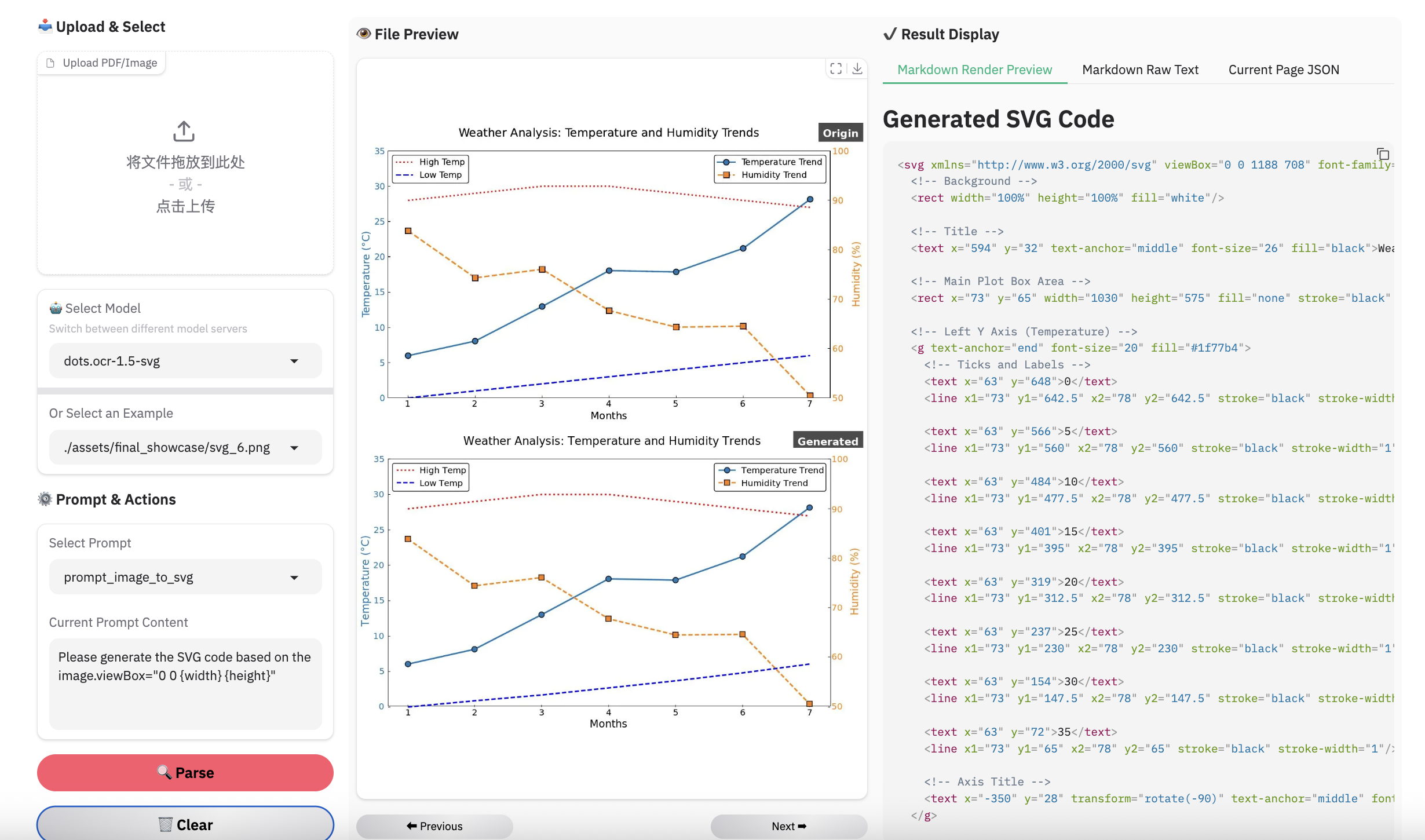 > **Note:**
> - Inferenced by dots.ocr-1.5-svg
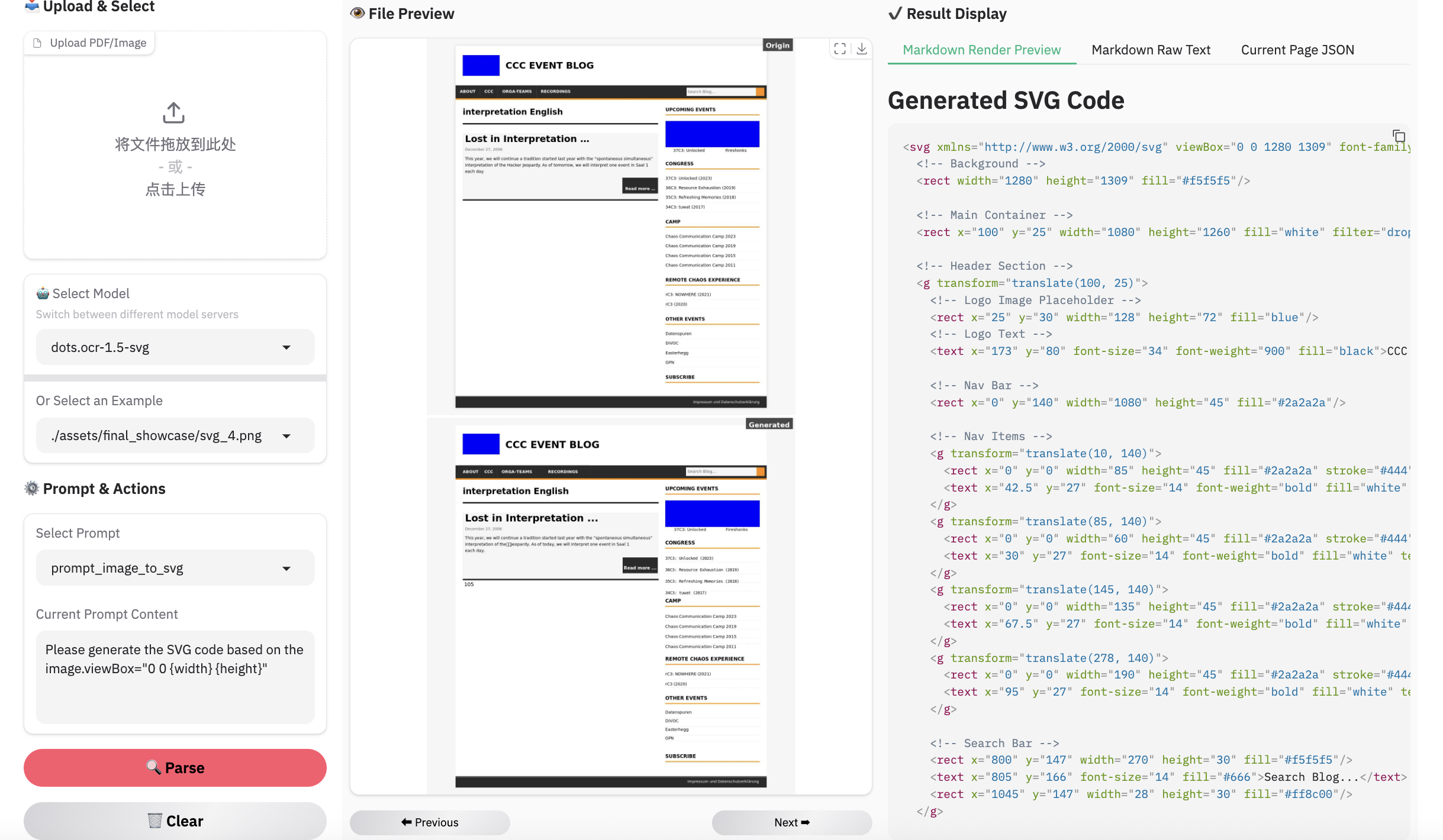
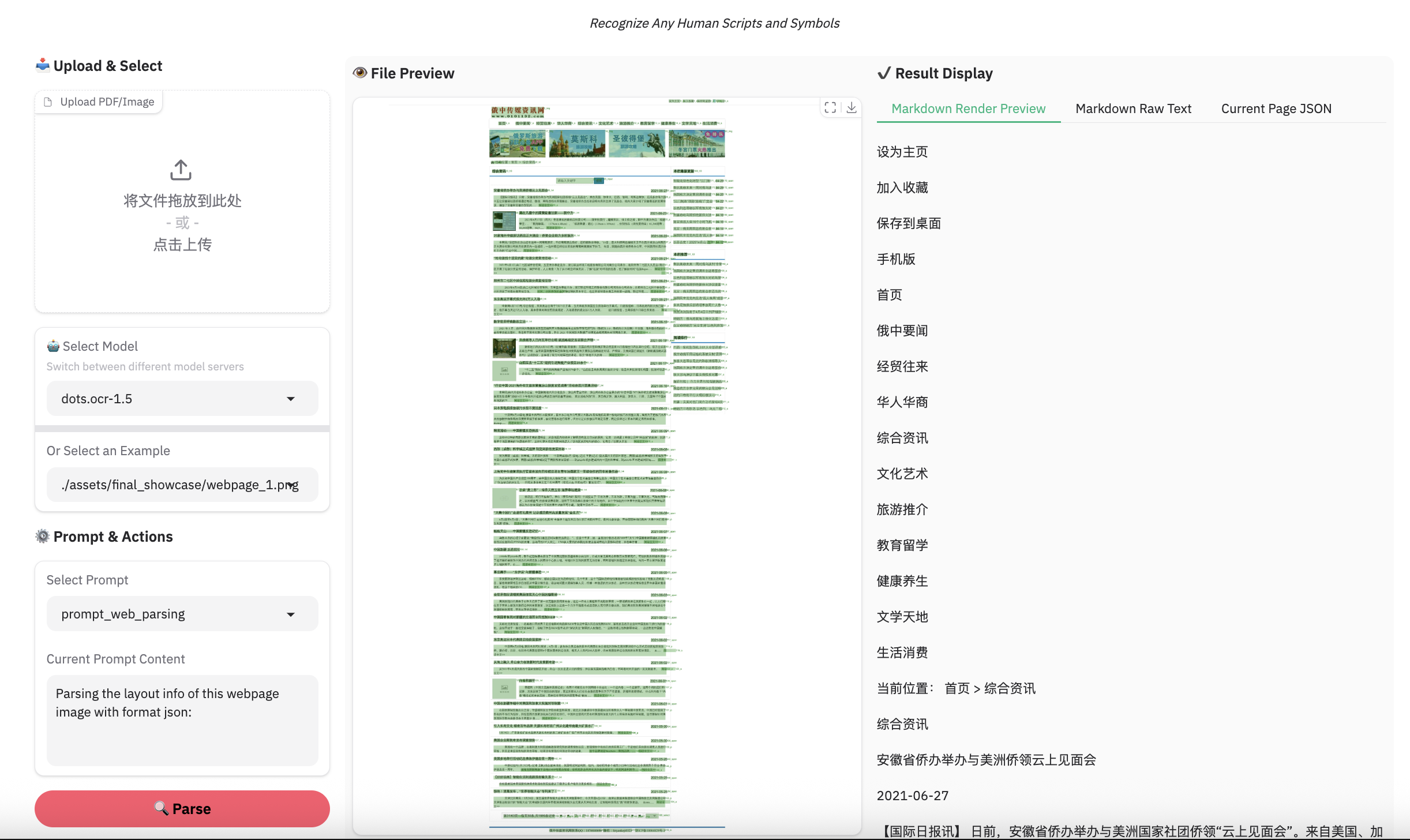
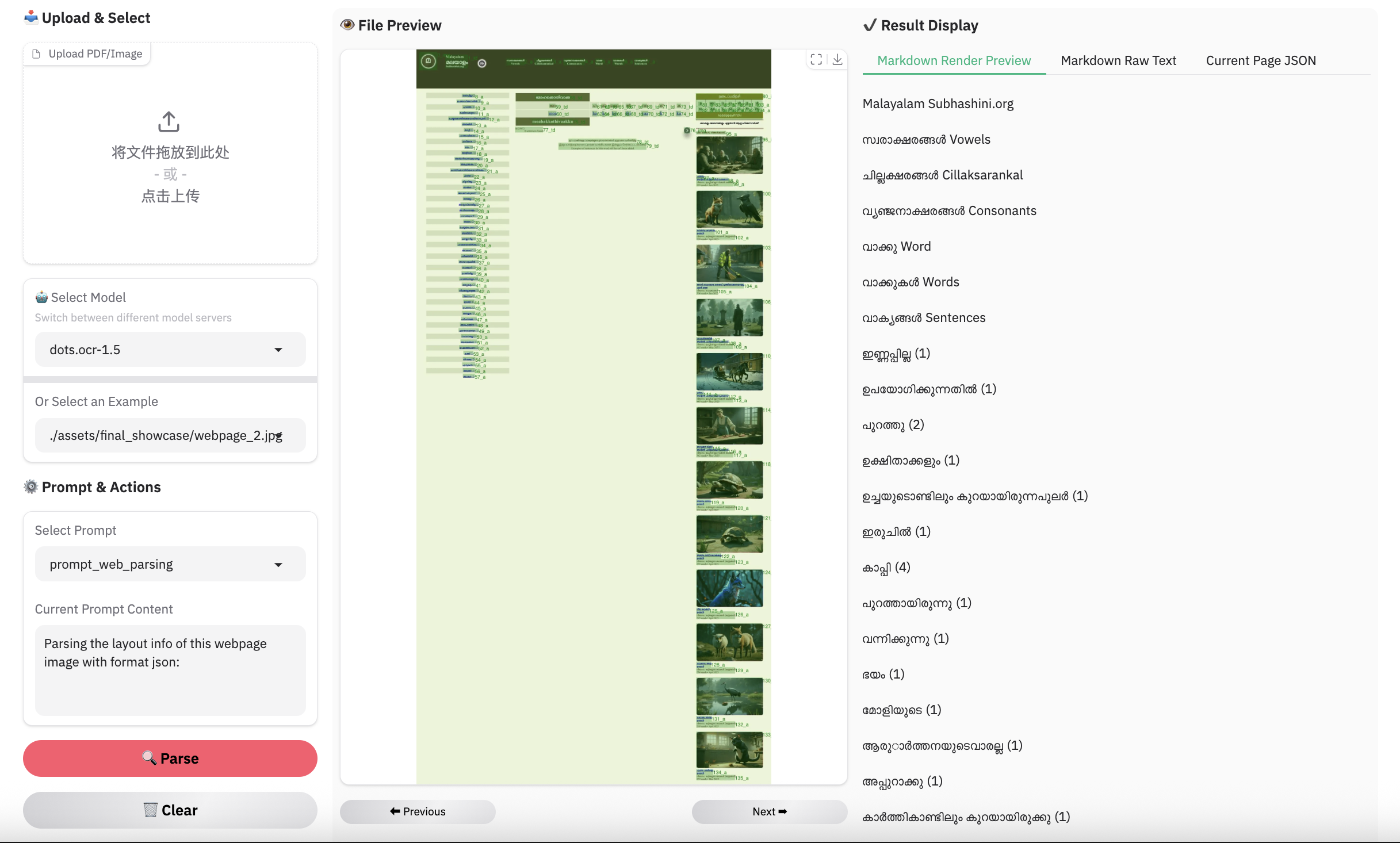
### Example for web parsing
> **Note:**
> - Inferenced by dots.ocr-1.5-svg
### Example for web parsing
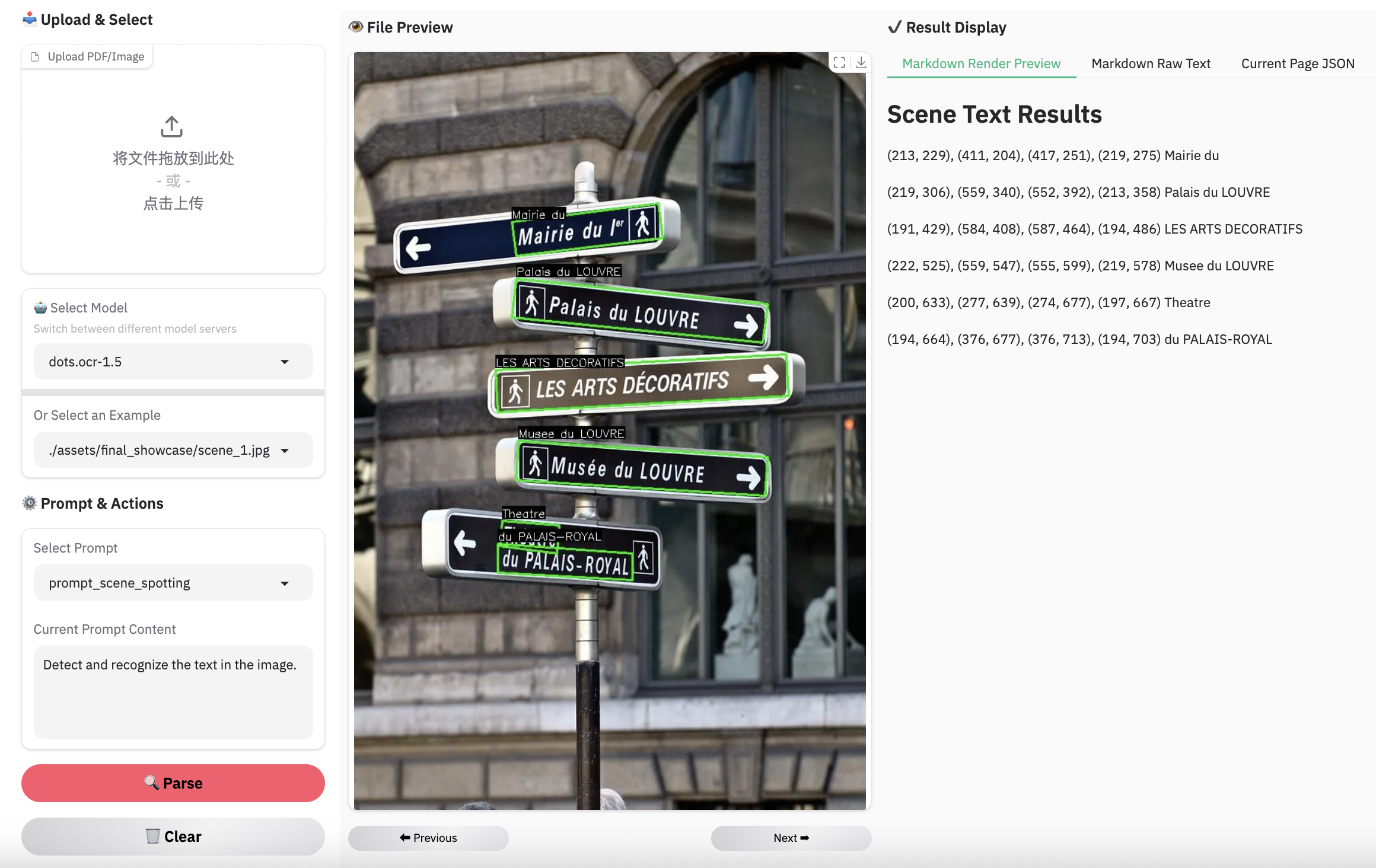
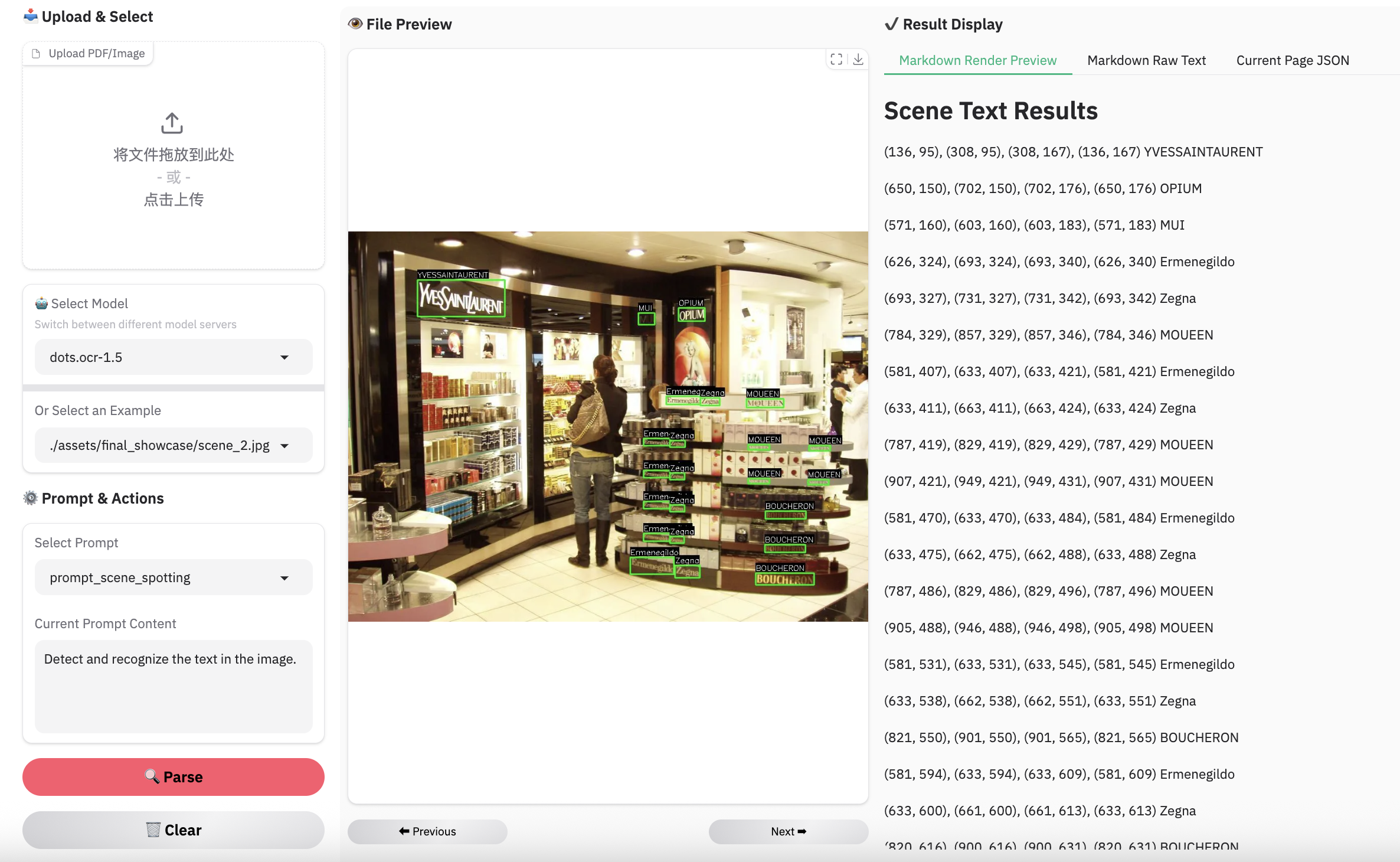
 ### Examples for scene spotting
### Examples for scene spotting
 # Limitation & Future Work
- **Complex Document Elements:**
- **Table&Formula**: The extraction of complex tables and mathematical formulas persists as a difficult task given the model's compact architecture.
- **Picture**: We have adopted an SVG code representation for parsing structured graphics; however, the performance has yet to achieve the desired level of robustness.
- **Parsing Failures:** While we have reduced the rate of parsing failures compared to the previous version, these issues may still occur occasionally. We remain committed to further resolving these edge cases in future updates.
# Citation
```BibTeX
@misc{li2025dotsocrmultilingualdocumentlayout,
title={dots.ocr: Multilingual Document Layout Parsing in a Single Vision-Language Model},
author={Yumeng Li and Guang Yang and Hao Liu and Bowen Wang and Colin Zhang},
year={2025},
eprint={2512.02498},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.02498},
}
```
# Limitation & Future Work
- **Complex Document Elements:**
- **Table&Formula**: The extraction of complex tables and mathematical formulas persists as a difficult task given the model's compact architecture.
- **Picture**: We have adopted an SVG code representation for parsing structured graphics; however, the performance has yet to achieve the desired level of robustness.
- **Parsing Failures:** While we have reduced the rate of parsing failures compared to the previous version, these issues may still occur occasionally. We remain committed to further resolving these edge cases in future updates.
# Citation
```BibTeX
@misc{li2025dotsocrmultilingualdocumentlayout,
title={dots.ocr: Multilingual Document Layout Parsing in a Single Vision-Language Model},
author={Yumeng Li and Guang Yang and Hao Liu and Bowen Wang and Colin Zhang},
year={2025},
eprint={2512.02498},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.02498},
}
```